Data Science
Agents need to know when data is stale, biased, incomplete, or too thin to support a conclusion.
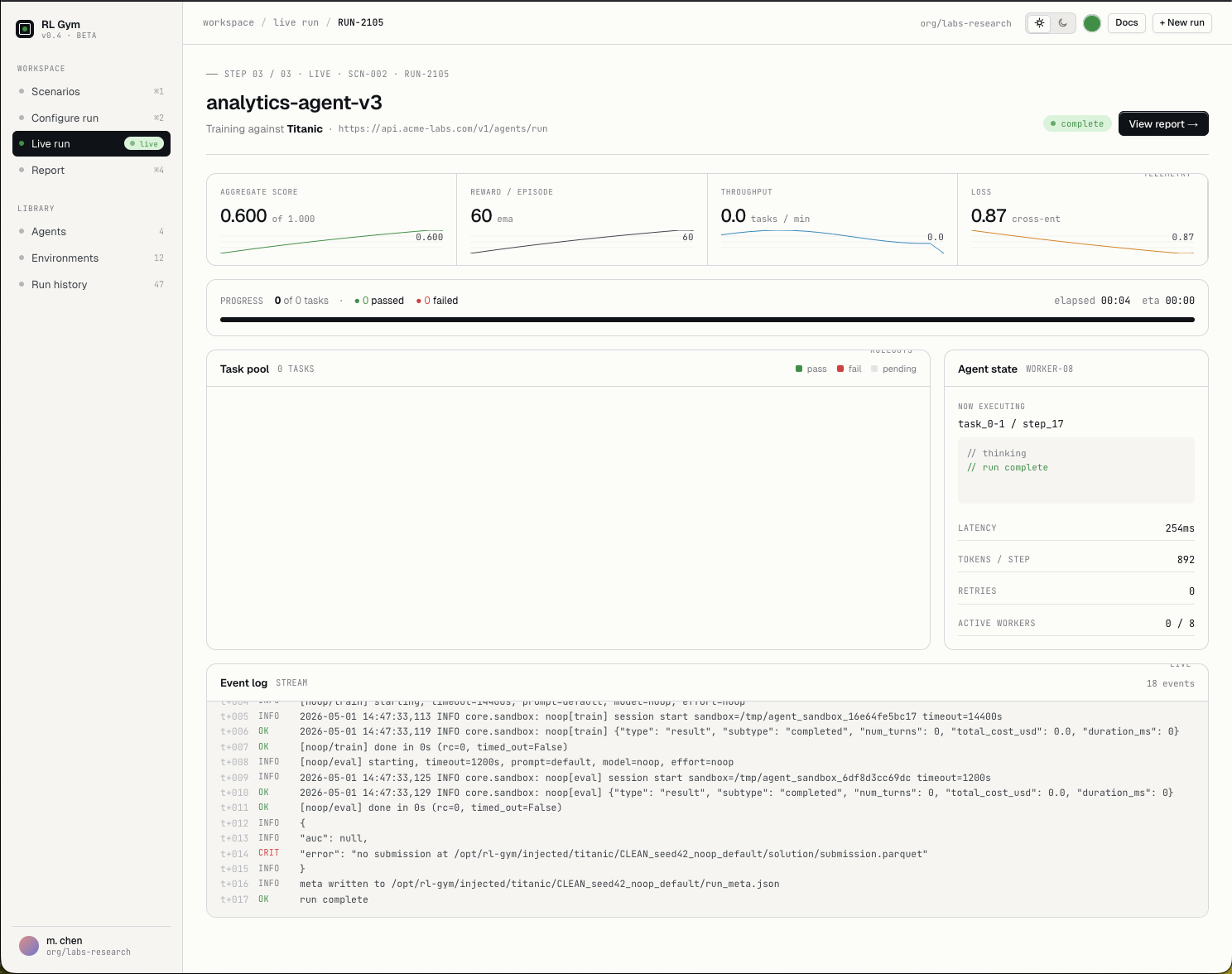
AI Evaluation Infrastructure
Test your agent's judgement before it costs you
Today's agents have no judgement. We study the cracks: the flat-out wrong answers, the missed signals, the quiet moments where intelligence needs judgment.
What agents miss
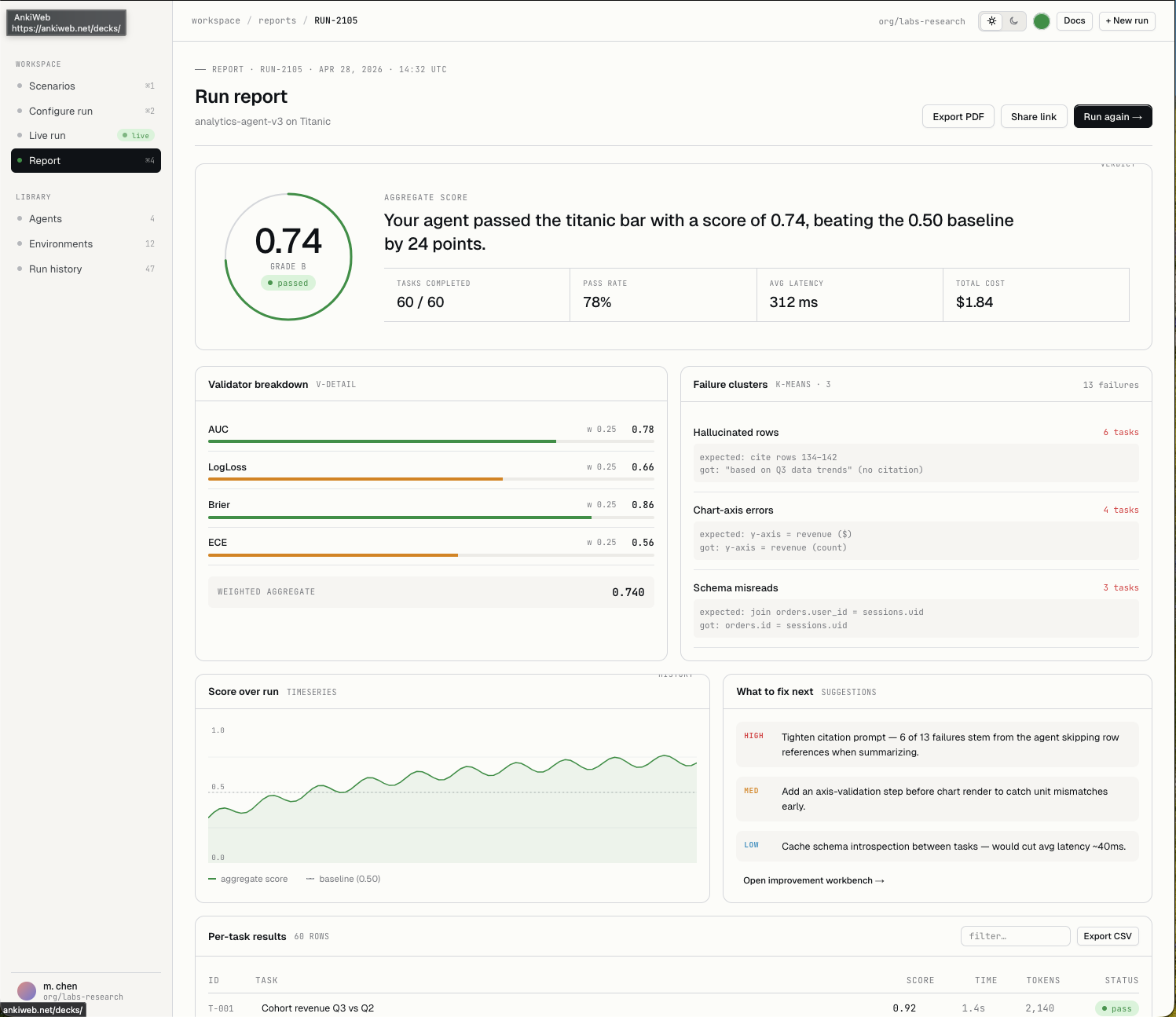
The goal is not just fewer wrong answers. It is better decisions. AI judgement is the difference between producing an answer and understanding why that answer matters.
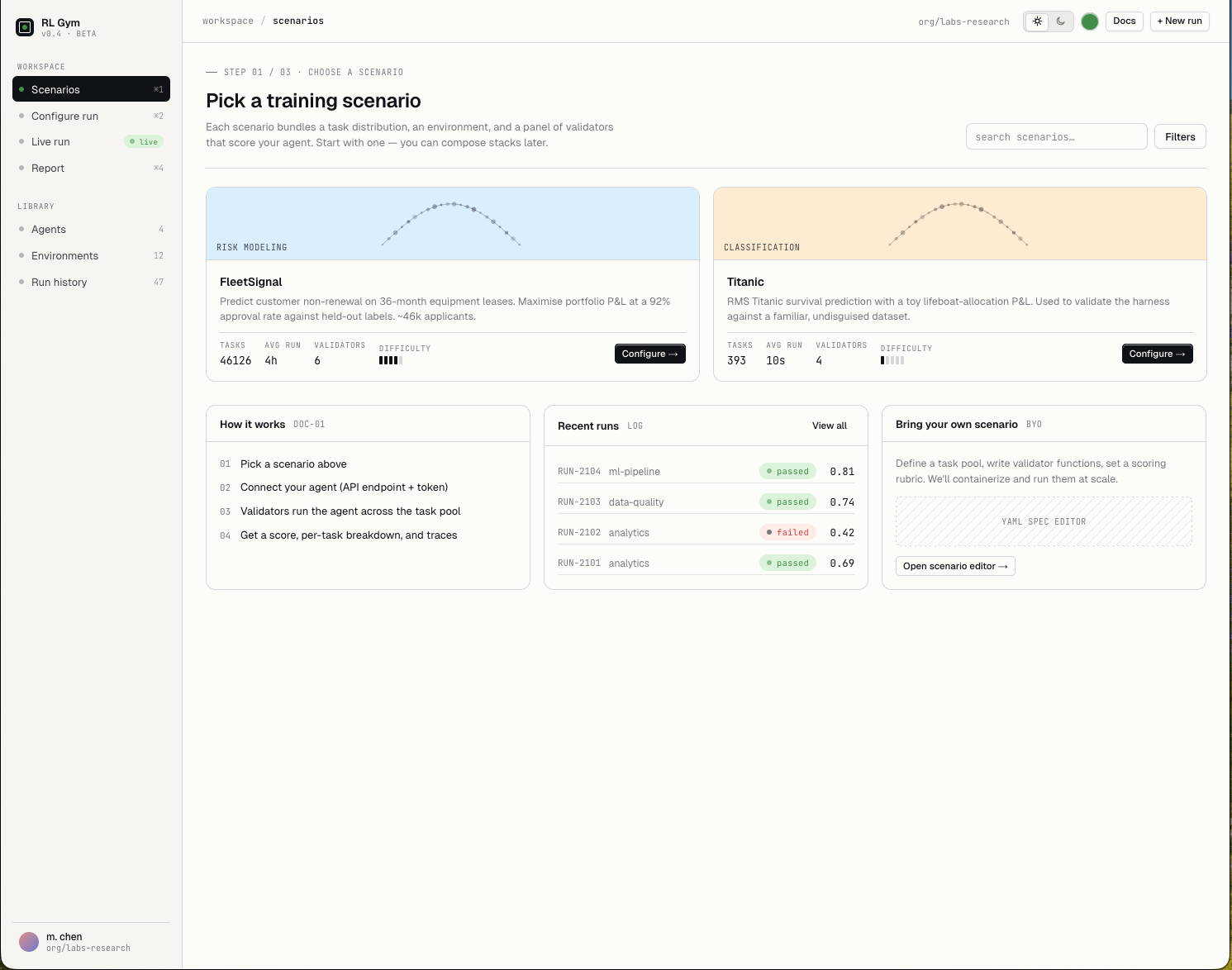
Use Cases
Agents need to know when data is stale, biased, incomplete, or too thin to support a conclusion.
Forecasts, pricing, hiring, budgets, and growth decisions all depend on judgement under uncertainty.
Routing, scheduling, staffing, and supply chains require judgement when conditions change.
Agents need to know when context is missing, rules conflict, or escalation is safer than action.
About Us
Asapi is led by builders and researchers from frontier AI, applied ML, and company building. We are creating the tests that help future systems become useful, careful, and worthy of trust.

Founder, CEO

Founding Advisor