Forecasting
Dataset-driven tasks that start simply, then force the agent to preserve intent, state, constraints, and intermediate results across many steps.
Tests based on real-world failures.
We build structured problem sets from issues observed while using state-of-the-art agents on a variety of real-world datasets, exposing brittle planning, poor recovery, unreliable tool use, and weak judgment.
We are building problem sets that make state-of-the-art agent weaknesses visible. Each case is grounded in issues found while testing state-of-the-art agents against practical datasets, then shaped into reproducible tasks, expected behaviors, and scoring notes.
Problem areas
Dataset-driven tasks that start simply, then force the agent to preserve intent, state, constraints, and intermediate results across many steps.
Cases where the agent must ask a clarifying question, refuse a bad assumption, or preserve user intent instead of rushing into an apparently plausible answer.
Tests that introduce stale facts, corrected requirements, hidden dependencies, or conflicting context to see what the agent keeps, drops, or invents.
Scenarios where tools error, return partial data, or contradict expectations, revealing whether the agent can verify, adapt, and recover.
Use Cases
We choose datasets and design problems based on real-world use cases that cause real-world issues. Whether it's issues for your business, your research, or your curiosity, failures in these areas are likely to lead to real-world harm, and improvements are likely to lead to real-world impact.
See test design processImpact matters. Which is why we focus on datasets that reflect real-world scenarios.
Define who would use the dataset and why they would be using it.
Challenge the agent on a variety of scenarios related to the problem domain.
Wherever the agent fails, document the circumstances and outcomes.
Workflow
Each problem set moves through the same loop: choose a scenario, configure the agent, watch execution, then review the report card for failures and scoring detail.
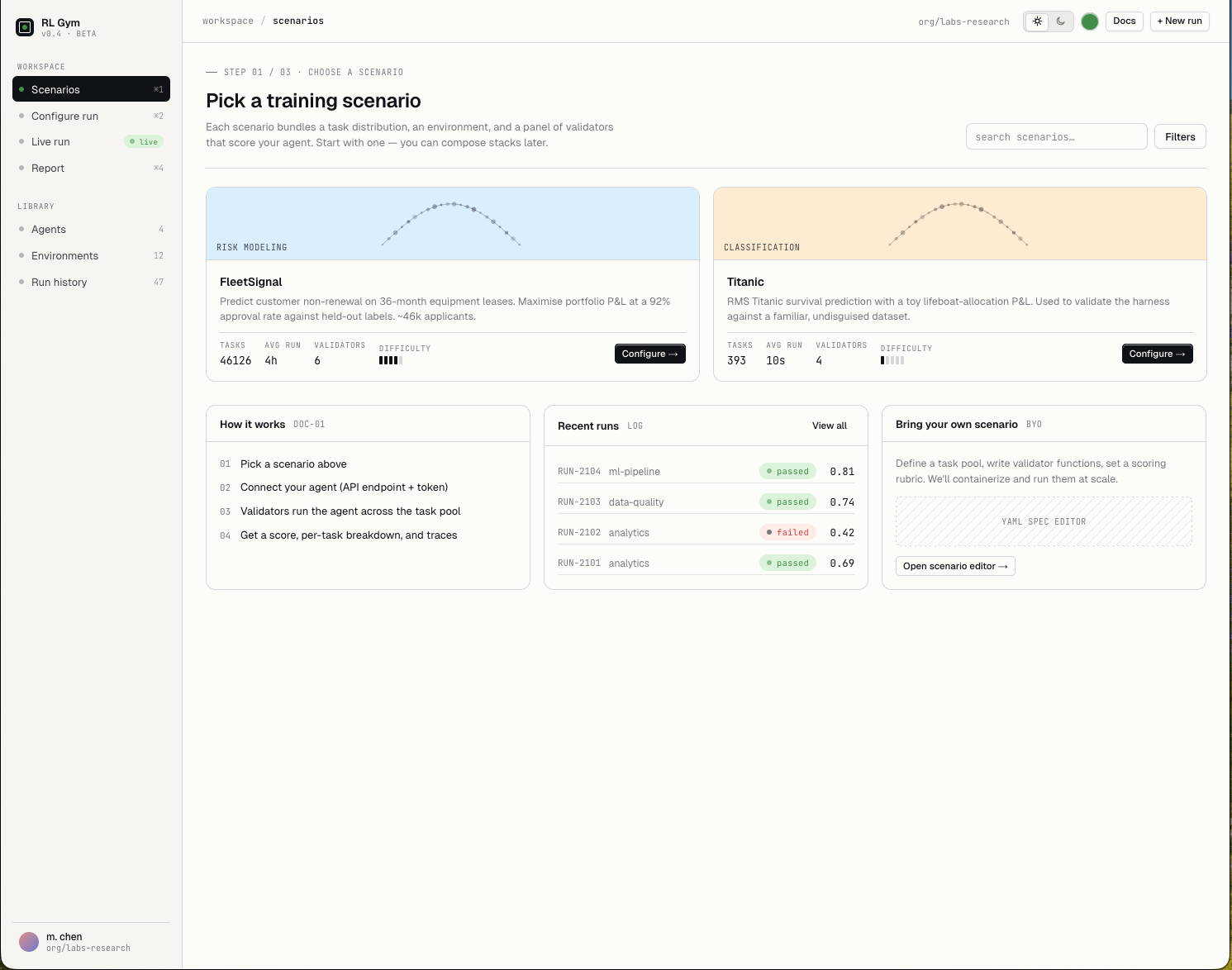
Start from a real-world dataset scenario with a task pool, environment, and validators that expose specific agent behaviors. Or choose and define your own to test what matters to you.
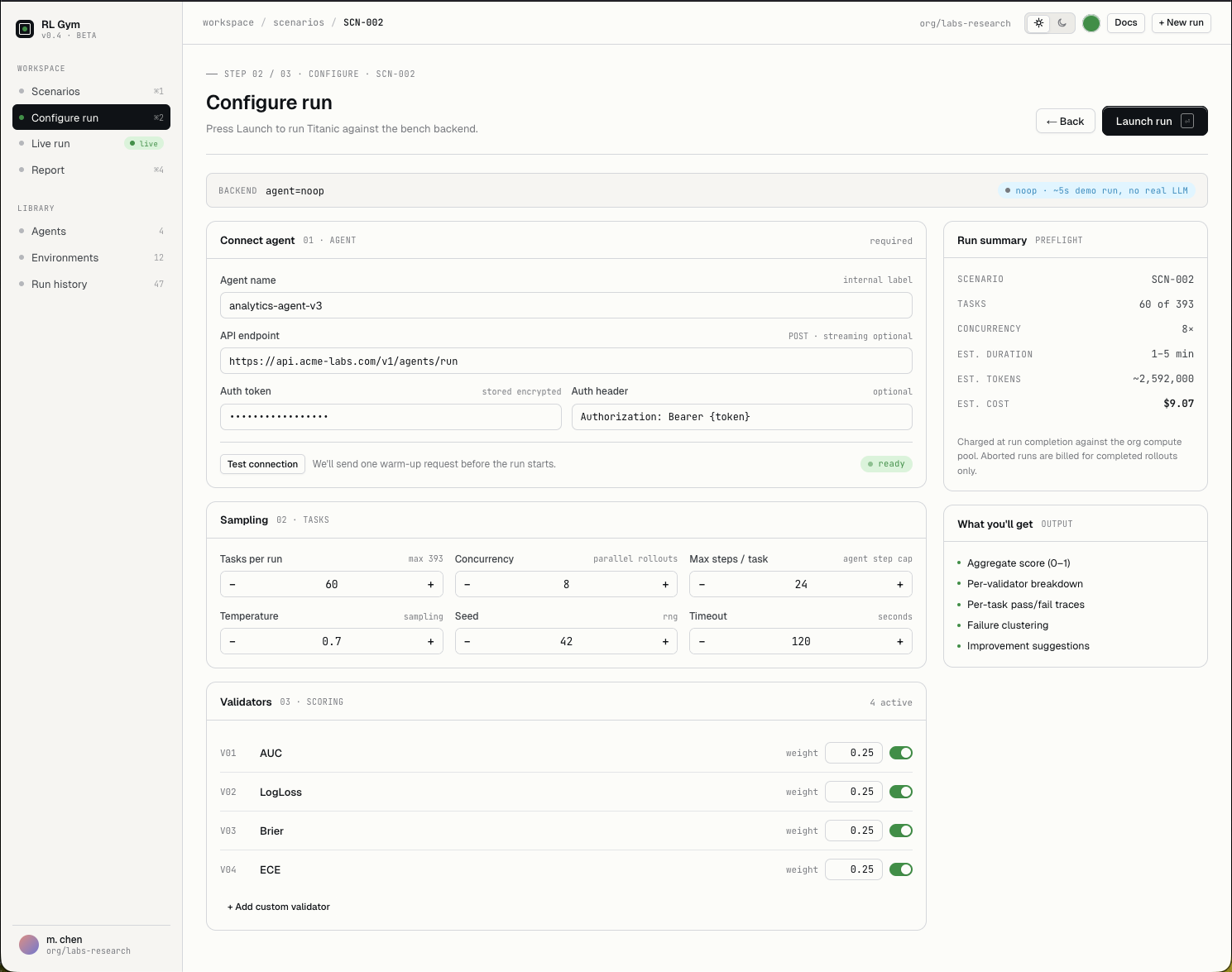
Connect your desired agent, set sampling and runtime limits, choose validators, and prepare the benchmark for a reproducible launch.
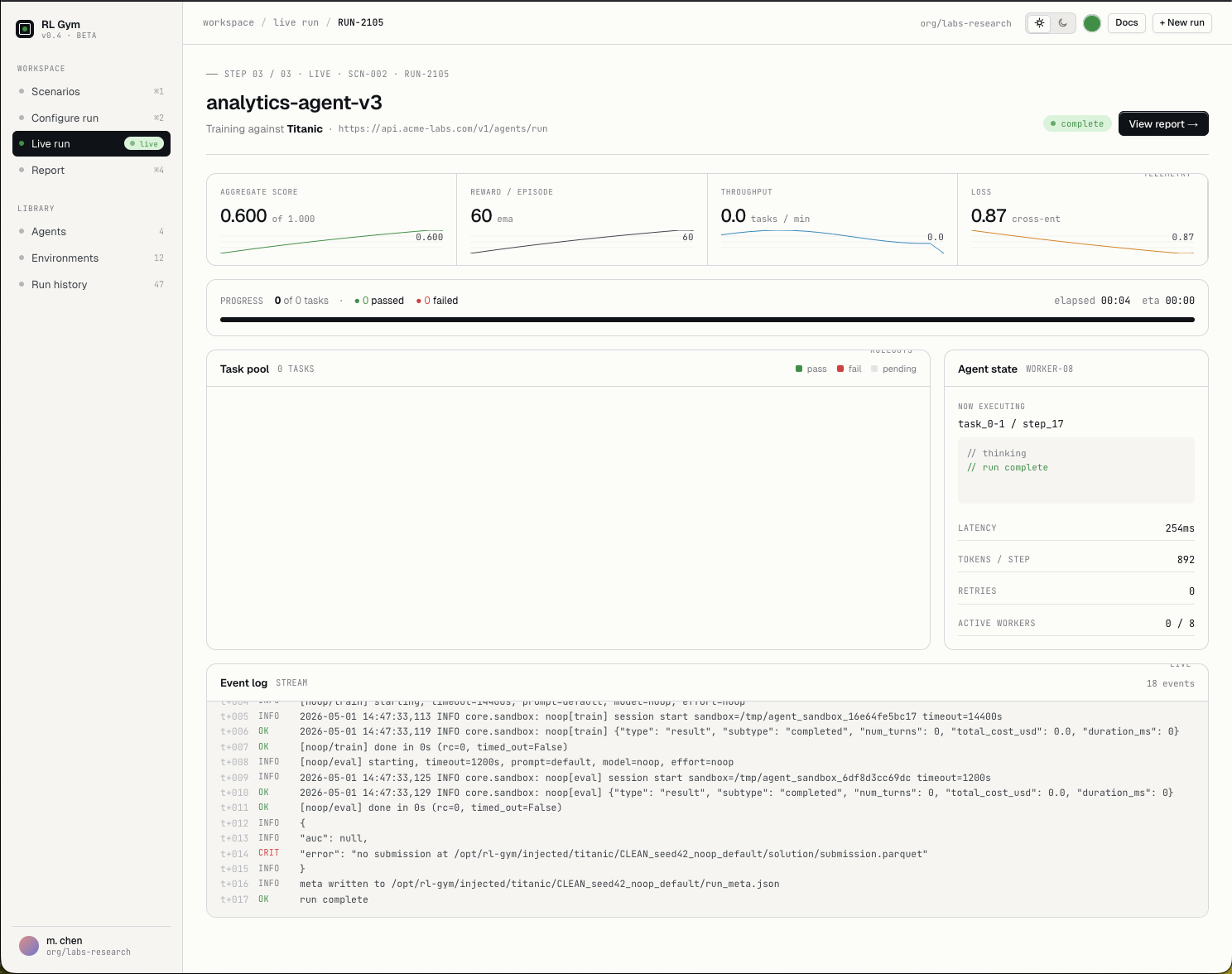
Observe the live task pool, event stream, retries, latency, and agent state as the model attempts the scenario.
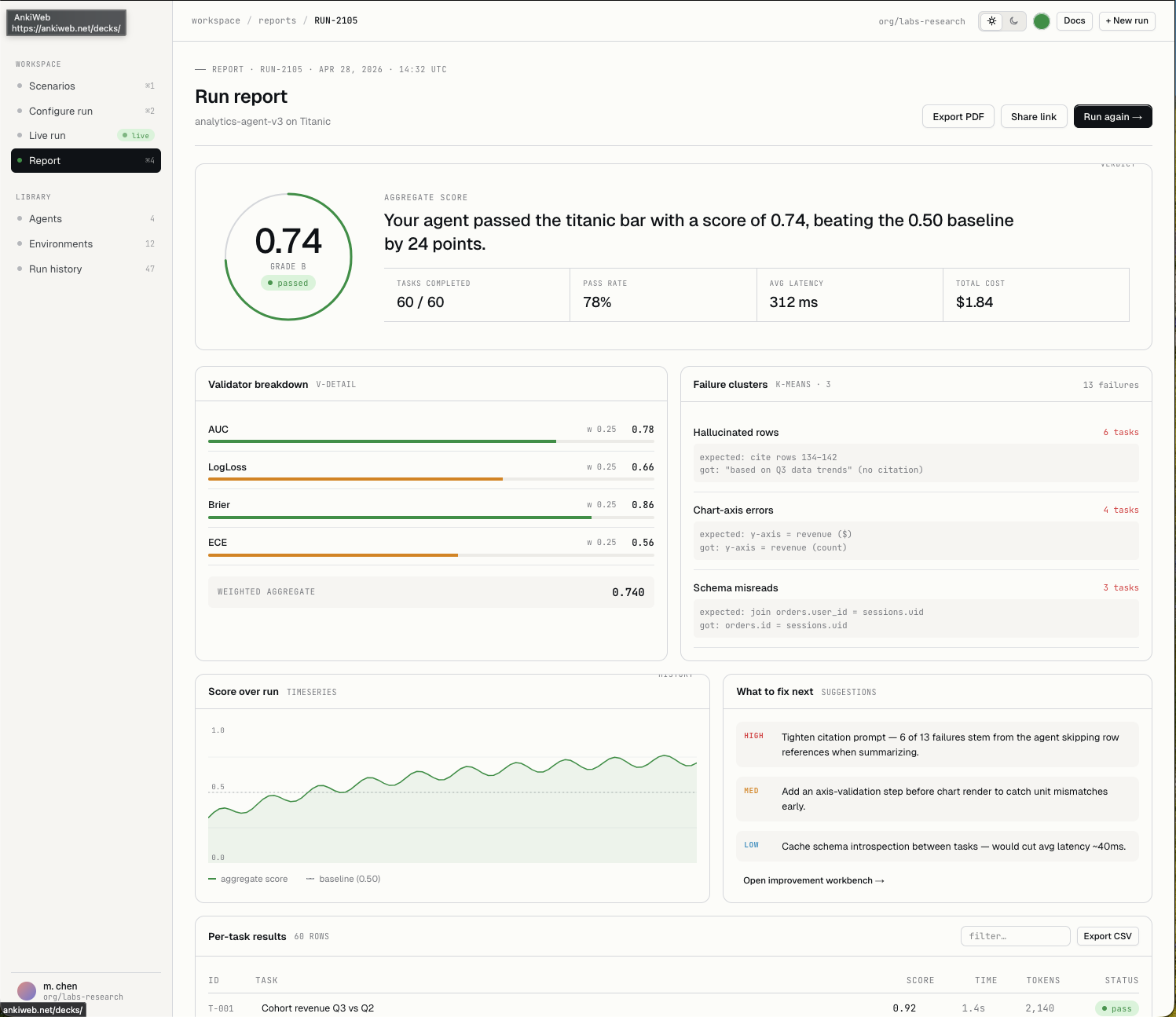
Turn the run into scores, validator breakdowns, failure clusters, per-task traces, and concrete improvement signals.
Next step
Define your problem, which agent you were using, what you expected to happen, and what actually happened. We'll review your submission, and if it fits our criteria, we'll turn it into a test case that can be used to track progress on the issue you found.